
Qwen/Qwen3.5-35B-A3B-Base on a FineWeb slice clipped to Common Crawl dumps published on or before 2017-06-30, then measures the leakage premium on Japanese equities — the R² gap between an honest chronological split and a stock-disjoint split that lets temporal leakage back in.
The example is a vehicle for three VESSL Cloud patterns you can reuse for any long-running training workload:
- One Object storage volume as the persistent backbone. The tokenized corpus, the evaluation data, and the trained checkpoints all live on a single volume that every batch job mounts.
- Terminal-driven training with
vesslctl. Edittrain.pylocally, submit with a wrapper script, and read metrics back from the job logs. No notebook, and no GPU lease held while you think. - Two arms on the same primitives. A single-H100 LoRA arm and an 8-GPU full-weight arm share the base model, the data, and the evaluation, so “train 2.6% of the parameters” and “train 100% of the parameters” can be compared head-to-head.

What this experiment found.
- Leakage is real. Both the base model and the continued-pretrained checkpoint show a statistically significant leakage premium on Kaggle JPX equities (both 95% CIs exclude zero).
- One continued-pretraining pass does not significantly reduce it. Both the LoRA and full-weight arms have a
premium_reductionCI that includes zero. - The evaluation protocol is the next lever. A ChronoGPT control showed the premium is nearly independent of the base model’s knowledge cutoff year, which implies evaluation construction drives much of the signal.
Prerequisites
- A VESSL Cloud account with credits (sign up)
- An organization with access to H100 SXM ×1 for the LoRA arm; the full-weight arm additionally needs a single-node H100 SXM ×8 spec
vesslctlinstalled and authenticated (vesslctl auth status)- Git and a local shell — the submit scripts run on your machine and shell out to
vesslctl - Kaggle credentials for the evaluation data — export
KAGGLE_USERNAMEandKAGGLE_KEYbefore data prep so the job can download the JPX Tokyo Stock Exchange Prediction dataset
Run the single-H100 LoRA arm
Create the cache volume
Everything that must survive between jobs — the tokenized FineWeb shards, the JPX prices, the trained adapter — lives on one Object storage volume:Then pick a single-H100 resource spec for the training job:
Run data prep once
Clone the cookbook and submit the one-off prep job. It streams FineWeb, keeps only Common Crawl dumps published on or before 2017-06-30, tokenizes the text with the Qwen3.5 tokenizer, and writes the shards to the volume:The prep job runs on a CPU spec in 30-60 minutes. Every training job after this mounts the same cache and skips data prep entirely.
Submit the training batch job
Each run lives on its own branch, so the container clones exactly the code you submitted:
submit.sh pushes your branch, calls vesslctl job create with the cache volume mounted at /root/.cache/aqr-finance, polls until the job reaches a terminal state, and writes the full job log to run.log. Inside the container, the job clones your branch, installs dependencies, runs python train.py (about 23 hours on one H100), then python eval.py (about 2 hours). To try a variant, edit train.py, commit on a fresh aqr-finance/<tag> branch, and rerun submit.sh.The 35B Mixture-of-Experts (MoE) base trains as a single process on one H100 80 GB: LoRA touches about 945M parameters (~2.6%) and VRAM peaks around 74 GB. The LoRA target list is the recipe’s main gotcha — Qwen3.5 mixes Gated DeltaNet and standard attention layers, and targeting only the standard
q/k/v/o projections freezes 75% of the model, so the loss diverges. The cookbook README documents the verified 12-entry target list.What a run costs and reports
Measured on VESSL Cloud, H100 SXM ×1. The full table is in the cookbook’sbenchmarks.md:
| Metric | Value |
|---|---|
| Wall time | ~23 h train + ~2 h eval |
| Cost | ~$60 (~$56 train + ~$4 eval at $2.39/hr) |
| Peak VRAM | ~74 GB |
| Trained parameters | ~945M (~2.6%) |
| Final train loss | 2.26 |
- Chronological split — train on years up to 2020, test on 2021 and later. This is the honest score; no future information can leak in.
- Stock-disjoint GroupKFold split — a stock never appears in both train and test, so memorizing stock identities earns nothing, but time periods mix freely, which lets temporal leakage back in.
- Leakage is real. The premium is statistically significant for both the base model (0.22) and the LoRA adapter (0.14); both CIs exclude zero.
- One pass does not remove it. The premium reduction (0.08) has a CI of [-0.04, 0.32], which crosses zero. Treat the recipe as a measuring instrument, not a leakage fix.
Scale up to the 8-GPU full-weight arm
A single 80 GB H100 physically cannot full-weight train a 35B model: weights, gradients, and optimizer state alone exceed 140 GB. The companion multigpu recipe shards them with FSDP2 (PyTorch Fully Sharded Data Parallel) across a single H100 SXM ×8 node using axolotl, training all 35B parameters at about 51 GB per GPU:| LoRA arm | Full-weight arm | |
|---|---|---|
| GPU | H100 SXM ×1 | H100 SXM ×8 (single node) |
| Trained parameters | ~945M (~2.6%) | 35B (100%) |
| Wall time | ~23 h | ~18.6 h |
| Cost | ~$60 | ~$386 |
| Peak VRAM | ~74 GB | ~51 GB per GPU |
The FSDP2 configuration that makes a 35B full-weight run fit on 8×80 GB is non-obvious: gradient accumulation must stay at 1 (anything higher accumulates unsharded full-model gradients and blows the VRAM budget), 8-bit optimizers fail on FSDP2’s DTensor, turning activation checkpointing off trades ~9 GB of headroom for about +32% throughput, and the checkpoint merge has to run as a separate single-GPU batch job to avoid NCCL watchdog timeouts. The multigpu README documents each invariant.
eval.py, the full-weight checkpoint and the LoRA adapter are scored on an identical measurement:
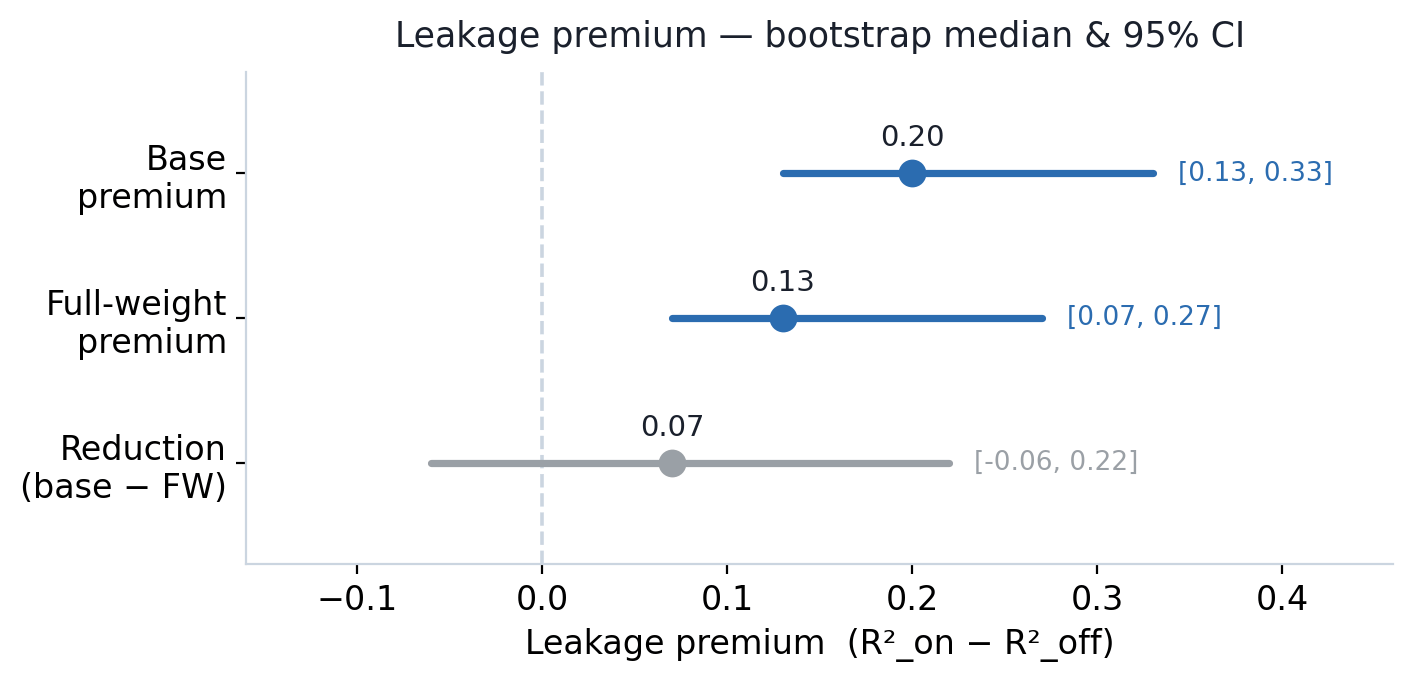
Things worth knowing
- Per-run cost is real. ~$60 for the LoRA arm and ~$386 for the full-weight arm, per run. At ~23 hours, a LoRA run is effectively a full-day slot — treat each run as expensive, and check spend with
vesslctl billing show. - This is a measurement, not an alpha recipe. Both arms’ chronological R² values are negative — neither model predicts JPX returns out-of-sample, which is expected for a leakage probe.
- More trainable parameters did not reduce leakage. The full-weight arm’s premium reduction (0.07, CI [-0.06, 0.22]) also crosses zero. On this measurement, the lever is the evaluation protocol, not the trainable-parameter count.
- The leakage measurement has its own precision limits. GroupKFold separates by stock identity but lets dates mix across folds, so the measured premium includes both temporal leakage and evaluation-construction noise. Embargoed and walk-forward robustness checks confirm the premium is real and not a split-edge artifact — but replacing the leaky-side GroupKFold with a purged time-series CV (a rolling window with a date-embargo gap) is still the open refinement lever. The companion blog post covers the ChronoGPT control experiment and the robustness checks in detail.
- Kaggle credentials must be staged before prep. If
prep.shskipped the JPX download,eval.pyrefuses to run. ExportKAGGLE_USERNAMEandKAGGLE_KEYbefore runningprep.sh(the script forwards them into the container), or stagestock_prices.csvon the cache volume manually. - The base model needs
trust_remote_code=True. Qwen3.5’s hybrid DeltaNet and Gated Attention architecture is not yet upstream intransformers. Pin the model revision for production use. - Branch hygiene. Every run pushes its own
aqr-finance/<tag>branch to origin. Use a fresh tag per run so reruns don’t clobber an earlier run’s commits.
Next steps
- Read the full analysis — The companion blog post covers the ChronoGPT control experiment, the embargoed and walk-forward robustness checks, the LoRA vs full-weight comparison, and what the results mean for a trading firm.
- Read the full recipe — Training scripts, submit helpers, and measured benchmarks live in vessl-ai/vessl-cloud-cookbook/aqr-finance, with the full-weight arm in aqr-finance/multigpu.
- Read the background — Kelly, Malamud, Schwab & Xu, “Scaling Point-in-Time Language Models”, and He, Lv, Manela & Wu, “Chronologically Consistent Large Language Models”.
- Port the pattern to your domain — A date-clipped corpus on a shared volume, batch-job continued pretraining, and a leakage check on a downstream task apply anywhere look-ahead bias matters: news sentiment, medical records, recommendation logs.
- Submit batch jobs from your CLI — See
vesslctl job createfor the full job submission flow.