
Qwen/Qwen3.5-35B-A3B-Base를 추가 사전학습(continued pretraining)한 다음, 일본 주식 데이터에서 누수 프리미엄(leakage premium)을 측정해요. 누수 프리미엄은 미래 정보 누수가 평가 점수를 얼마나 부풀렸는지 보여주는 값이에요. 계산 방법은 아래 실행 비용과 측정 결과에서 설명해요.
이 예제에서 쓰는 VESSL Cloud 패턴 세 가지는 다른 장시간 학습 워크로드에도 그대로 가져다 쓸 수 있어요.
- 볼륨 하나에 모든 데이터를 보관해요. 학습 데이터, 평가 데이터, 학습이 끝난 체크포인트까지 전부 Object storage 볼륨 하나에 두고, 모든 배치 잡이 같은 볼륨을 마운트해요.
- 학습은 터미널에서
vesslctl로 진행해요.train.py를 로컬에서 수정하고, 스크립트로 제출하고, 결과 지표는 Job 로그에서 확인해요. Jupyter notebook을 띄워 둘 필요가 없고, 코드를 고치는 동안 GPU를 잡아 두지 않으니 그만큼 비용도 아껴요. - 레시피 하나를 두 가지 버전으로 돌려요. 단일 H100에서 도는 LoRA 버전과 GPU 8장에서 모든 파라미터를 학습하는 full-weight 버전이 베이스 모델, 데이터, 평가 코드를 공유해요. 그래서 “파라미터 2.6%만 학습”한 결과와 “100% 전부 학습”한 결과를 같은 기준으로 비교할 수 있어요.

이 실험의 결론.
- 누수는 실제로 있었어요. 베이스 모델과 추가 사전학습한 체크포인트 모두 통계적으로 유의한 누수 프리미엄을 보였어요.
- 한 번의 추가 사전학습으로는 누수가 안 줄어들어요. LoRA/full-weight 두 버전 모두
premium_reduction신뢰구간이 0을 포함해요. - 평가 프로토콜의 개선이 필요하다는 결론이 났어요. 학습 데이터 마감 연도(knowledge cutoff)가 다른 모델로 대조실험(ChronoGPT)을 해 보니, 마감 연도가 2011년이든 2024년이든 누수 프리미엄은 거의 그대로였어요. 누수의 상당 부분이 모델이 아니라 평가 방식에서 나온다는 뜻이에요. 그래서 비슷한 실험을 계획하고 있다면, 학습량을 늘리기보다 평가 방식을 개선하는 쪽을 먼저 검토해 보길 권해드려요.
사전 준비
- 크레딧이 충전된 VESSL Cloud 계정(가입하기)
- H100 SXM ×1을 쓸 수 있는 조직. full-weight 버전까지 돌리려면 단일 노드 H100 SXM ×8 스펙도 필요해요.
- 인증된
vesslctl(vesslctl auth status) - Git과 로컬 셸. 제출 스크립트는 내 컴퓨터에서 실행되고, 내부에서
vesslctl을 호출해요. - 평가 데이터를 받기 위한 Kaggle 자격 증명. 데이터 준비 전에
KAGGLE_USERNAME과KAGGLE_KEY를 export해 두면 Job이 JPX Tokyo Stock Exchange Prediction 데이터셋을 내려받아요.
단일 H100 LoRA 버전 실행하기
캐시 볼륨 만들기
Job이 끝난 뒤에도 남아 있어야 하는 데이터, 즉 토큰화한 FineWeb 샤드(shard, 분할 단위), JPX 주가 데이터, 학습된 어댑터는 전부 Object storage 볼륨 하나에 보관해요.학습 배치 잡에 쓸 단일 H100 리소스 스펙도 골라 두세요.
데이터 준비 한 번만 돌리기
쿡북을 클론하고 일회성 준비 Job을 제출해요. 이 Job은 FineWeb을 스트리밍하면서 2017년 6월 이전에 수집된 데이터만 남기고, Qwen3.5 토크나이저로 토큰화한 샤드를 볼륨에 저장해요.준비 Job은 CPU 스펙에서 30-60분 정도 걸려요. 이후 제출하는 모든 학습 Job은 같은 캐시를 마운트하기 때문에 데이터 준비 단계를 건너뛰어요.
학습 배치 잡 제출하기
실행마다 전용 브랜치를 쓰기 때문에, 컨테이너는 내가 제출한 시점의 코드를 그대로 클론해요.
submit.sh는 브랜치를 푸시하고, 캐시 볼륨을 /root/.cache/aqr-finance에 마운트한 채 vesslctl job create를 호출하고, Job이 끝날 때까지 폴링(polling, 주기적으로 상태를 조회)한 뒤 전체 Job 로그를 run.log로 저장해요. 컨테이너 안에서는 브랜치 클론과 의존성 설치에 이어 python train.py(H100 한 장에서 약 23시간), python eval.py(약 2시간)가 차례로 실행돼요. 설정을 바꿔서 다시 실험하려면 train.py를 수정하고 새 aqr-finance/<tag> 브랜치에 커밋한 뒤 submit.sh를 다시 실행하면 돼요.35B MoE(Mixture-of-Experts) 베이스 모델이 H100 80 GB 한 장에서 단일 프로세스로 학습돼요. LoRA로 학습하는 파라미터는 약 9억 4,500만 개(전체의 약 2.6%)이고, VRAM은 최대 약 74 GB까지 사용해요. 이 레시피에서 가장 주의해야 할 부분은 LoRA 타깃 목록이에요. Qwen3.5는 Gated DeltaNet 레이어와 표준 어텐션 레이어를 섞어 쓰는 구조라서, 표준
q/k/v/o 프로젝션만 타깃으로 지정하면 모델의 75%에는 어댑터가 아예 붙지 않고, 그 상태로는 손실이 발산해요. 검증된 12개 타깃 목록은 쿡북 README에 정리되어 있어요.실행 비용과 측정 결과
VESSL Cloud H100 SXM ×1에서 실측한 값이에요. 전체 표는 쿡북의benchmarks.md에 있어요.
| 항목 | 값 |
|---|---|
| 실제 소요 시간 | 학습 약 23시간 + 평가 약 2시간 |
| 비용 | 약 $60(학습 약 $56 + 평가 약 $4, 시간당 $2.39 기준) |
| 최대 VRAM | 약 74 GB |
| 학습 파라미터 | 약 9억 4,500만 개(약 2.6%) |
| 최종 학습 손실 | 2.26 |
- 시간순 분할(chronological split): 2020년까지의 데이터로 학습하고 2021년 이후 데이터로 테스트해요. 미래 정보가 개입할 수 없어서, 모델의 실제 성능을 보여주는 기준 점수예요.
- 종목 분리(stock-disjoint) 그룹 K-폴드(GroupKFold) 분할: 같은 종목이 학습과 테스트 양쪽에 들어가지 않게 나누되, 시간대는 섞어요. 그래서 종목을 외워서 점수를 올릴 수는 없고, 미래 정보 누수의 효과만 점수에 더해져요.
- 누수는 실제로 있어요. 베이스 모델(0.22)과 LoRA 어댑터(0.14) 모두 프리미엄의 95% 신뢰구간(confidence interval)이 0을 포함하지 않아요. 즉 통계적으로 유의해요.
- 한 번의 학습으로 누수가 사라지지는 않아요. 프리미엄 감소폭(0.08)은 신뢰구간이 [-0.04, 0.32]로 0을 포함해서, 통계적으로 유의하지 않아요. 이 레시피는 누수를 없애는 방법이 아니라 측정하는 도구예요.
full-weight 버전으로 확장하기
H100 80 GB 한 장으로는 35B 모델의 full-weight 학습이 물리적으로 불가능해요. 가중치, 그래디언트, 옵티마이저 상태만 더해도 140 GB가 넘기 때문이에요. 같은 쿡북의 multigpu 레시피는 axolotl과 FSDP2(PyTorch Fully Sharded Data Parallel)로 이 세 가지를 단일 노드 H100 8장에 나눠 올려서, GPU당 약 51 GB로 35B 파라미터 전체를 학습해요.| LoRA 버전 | full-weight 버전 | |
|---|---|---|
| GPU | H100 SXM ×1 | H100 SXM ×8(단일 노드) |
| 학습 파라미터 | 약 9억 4,500만 개(약 2.6%) | 35B 전체(100%) |
| 실제 소요 시간 | 약 23시간 | 약 18.6시간 |
| 비용 | 약 $60 | 약 $386 |
| 최대 VRAM | 약 74 GB | GPU당 약 51 GB |
35B full-weight 학습을 80 GB GPU 8장에 맞춰 넣는 FSDP2 설정에는 놓치기 쉬운 제약이 몇 가지 있어요. 그래디언트 누적(gradient accumulation)은 1로 고정해야 해요. 값을 키우면 샤딩되지 않은 전체 모델 그래디언트가 GPU마다 쌓여서 80 GB를 넘어가요. 8비트 옵티마이저는 FSDP2의 DTensor와 호환되지 않아요. 활성화 체크포인팅(activation checkpointing)을 끄면 메모리를 약 9 GB 더 쓰는 대신 처리량이 약 32% 높아져서, 이 레시피에서는 꺼 두었어요. 마지막으로 체크포인트 병합은 NCCL 타임아웃을 피하기 위해 별도의 단일 GPU 배치 잡으로 실행해야 해요. 각 설정의 배경은 multigpu README에 정리되어 있어요.
eval.py를 쓰기 때문에, full-weight 체크포인트와 LoRA 어댑터를 완전히 같은 조건에서 평가할 수 있어요.
알아두면 좋은 것들
- 한 번 돌릴 때마다 비용이 적지 않아요. LoRA 버전은 1회 약 $60, full-weight 버전은 약 $386이 들어요. LoRA 학습만 약 23시간이라, 한 번 돌리면 사실상 하루가 지나가요. 실험 횟수를 미리 계획하고, 지출은
vesslctl billing show로 확인해 주세요. - 수익을 내는 모델을 만드는 레시피가 아니에요. 두 버전 모두 시간순 분할 R²가 음수예요. 어느 모델도 학습에 쓰지 않은 구간(out-of-sample)에서는 다음 날 수익률을 예측하지 못해요. 이 레시피의 목적이 누수 측정이니, 예상된 결과예요.
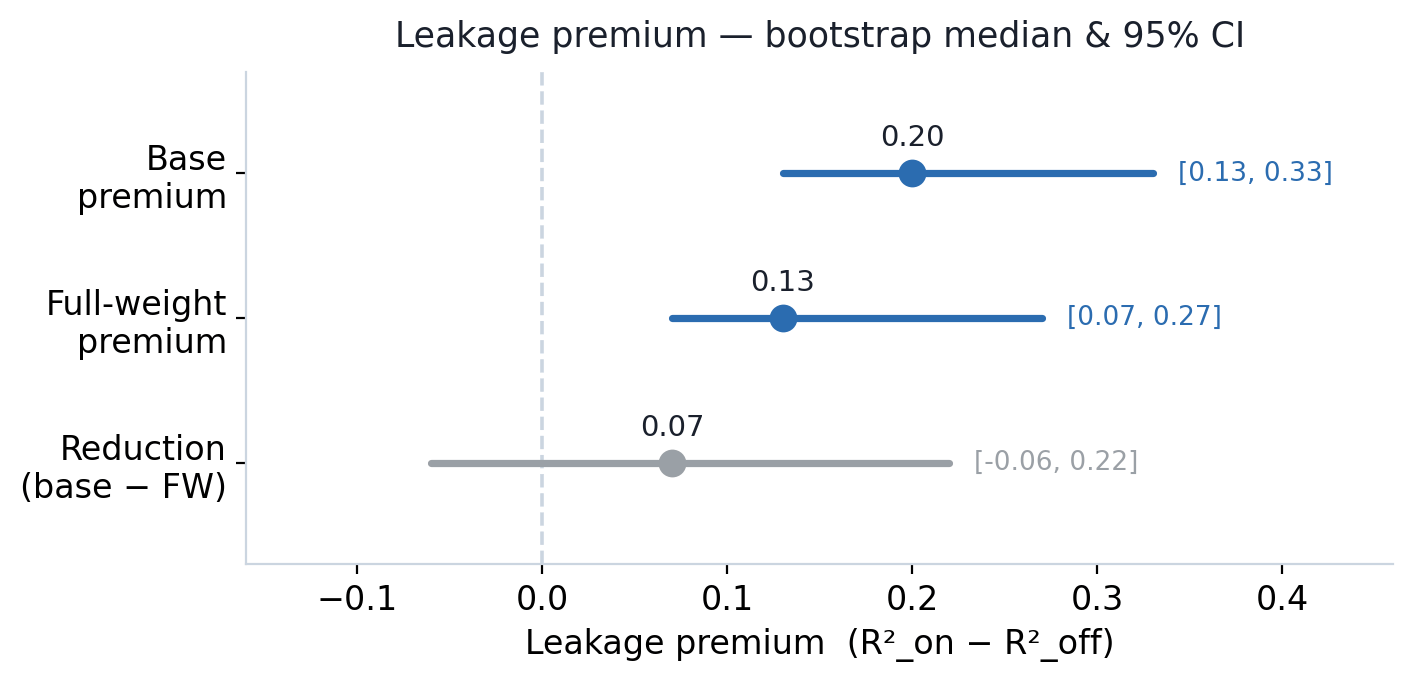
- 파라미터를 더 많이 학습해도 누수는 줄지 않았어요. full-weight 버전의 프리미엄 감소폭(0.07)도 신뢰구간이 [-0.06, 0.22]로 0을 포함해요. 누수를 통제하는 건 학습 파라미터 수가 아니라 평가 방식이라는 뜻이에요.
- 누수 측정 방법 자체에도 정밀도의 한계가 있어요. 그룹 K-폴드 분할은 종목 단위로 학습과 테스트를 나누지만, 학습 폴드에는 여전히 여러 시점의 데이터가 섞여요. 그래서 측정된 누수 프리미엄에는 실제 시간축 누수뿐 아니라 평가 설계에서 비롯된 노이즈도 포함돼요. embargo(경계 구간 제외) 검증과 walk-forward(시간순 반복 평가)도 돌려서 프리미엄이 분석 방식과 무관하게 실재함을 확인했어요. 단, 누수를 측정하는 GroupKFold를 날짜까지 격리하는 purged time-series CV(날짜가 섞이지 않는 시계열 교차 검증)로 교체하는 건 아직 시도하지 않은 다음 단계예요. 블로그 포스트에서 ChronoGPT 대조실험과 견고성 검증 결과를 확인할 수 있어요.
- Kaggle 자격 증명은 데이터 준비 전에 설정해야 해요. JPX 데이터가 없으면
eval.py는 실행되지 않아요.prep.sh를 돌리기 전에KAGGLE_USERNAME과KAGGLE_KEY를 export해 두거나(값은 컨테이너로 전달돼요),stock_prices.csv파일을 캐시 볼륨에 직접 올려 두세요. - 베이스 모델을 불러올 때
trust_remote_code=True가 필요해요. Qwen3.5의 하이브리드 아키텍처(DeltaNet + Gated Attention)는 아직transformers라이브러리에 정식으로 포함되지 않았어요. 프로덕션에서 쓸 때는 모델 리비전을 고정해 주세요. - 실행마다 새 브랜치를 쓰세요. 실행할 때마다 전용
aqr-finance/<tag>브랜치가 origin에 푸시돼요. 태그를 재사용하면 이전 실행의 커밋을 덮어쓸 수 있으니, 실행할 때마다 새 태그를 만들어 주세요.
다음 단계
- 전체 분석 읽어보기: 블로그 포스트에서 ChronoGPT 대조실험, embargo/walk-forward 견고성 검증, LoRA 비교 결과, 트레이딩 관점의 시사점을 확인하세요.
- 전체 레시피 읽어보기: 학습 스크립트, 제출 스크립트, 실측 벤치마크는 vessl-ai/vessl-cloud-cookbook/aqr-finance에 있어요. full-weight 버전은 aqr-finance/multigpu를 참고하세요.
- 배경 논문 읽어보기: Kelly, Malamud, Schwab & Xu의 “Scaling Point-in-Time Language Models”와 He, Lv, Manela & Wu의 “Chronologically Consistent Large Language Models”를 참고하세요.
- 내 도메인에 적용하기: 날짜로 잘라낸 학습 데이터를 공유 볼륨에 두고, 배치 잡으로 추가 사전학습하고, 다운스트림 과제에서 누수를 확인하는 워크플로우는 뉴스 감성 분석, 의료 기록, 추천 로그처럼 미래 정보 누수가 문제가 되는 모든 도메인에 적용할 수 있어요.
- CLI에서 배치 잡 제출하기: 전체 배치 잡 제출 흐름은
vesslctl job create을 참고해 주세요.